Canevas d'analyse rétrospective sans blâme
Ce modèle de post-mortem « sans blâme » vous aide à rassembler des informations sur les incidents survenus en production.
Ce modèle de Post-Mortem « sans reproche » vous aide à réunir des informations sur les incidents survenus en production. Suivre ce processus signifie que les ingénieurs dont les actions ont contribué à un accident peuvent fournir un compte rendu détaillé de :
quelles actions ils ont prises à quelle heure,
quels effets ils ont observés,
les attentes qu'ils avaient,
hypothèses qu'ils avaient faites,
leur compréhension du planning des événements tels qu’ils se sont déroulés.
et qu'elles peuvent donner ce compte-rendu détaillé sans crainte de punition ni de représailles.
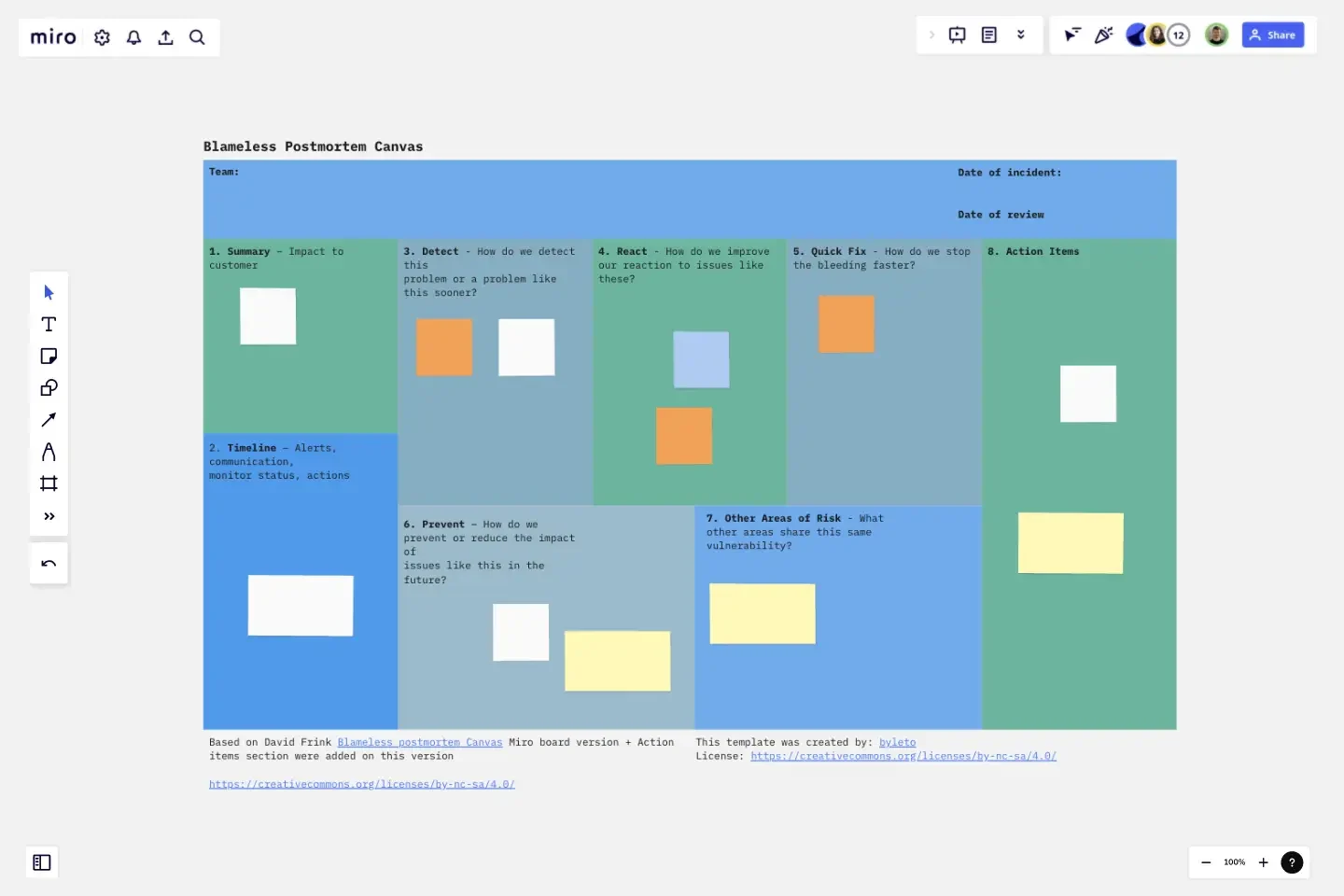
Le postmortem Blameless comprend les sections suivantes
Étape 1 : Résumé (prérenseignement avant la réunion)
Un résumé de haut niveau du ticket, se concentrant sur ce qui est connu à ce stade et l'impact ressenti par le client. Gardez cela en une ou deux phrases.
Étape 2 : Planification Approximative (préremplir avant la réunion)
Un planning approximatif du ticket. Selon la vitesse à laquelle le ticket a été traité, ce planning pourrait s’étendre de quelques minutes à quelques heures, voire quelques jours. Si votre principal objectif est d'améliorer les temps de réponse de l’équipe lors des situations d'urgence, vous voudrez que cela se fasse à la seconde près.
Lorsque vous saisissez le planning, assurez-vous d'inclure :
Quand le ticket a été signalé et par qui/quel processus
Quelles actions ont été prises
Quand la communication a été établie au sein de l'équipe et à l'extérieur
Idées de remédiation
Lorsque vous vous réunissez pour discuter du ticket, invitez toutes les personnes qui ont travaillé sur le ticket. Cela inclut l'équipe de service de production ainsi que les membres de l'équipe d'assistance à la clientèle qui ont pu être impliqués.
Passez en revue le résumé, examinez le calendrier et ajoutez les parties manquantes, puis passez aux idées de remédiation.
Ces questions sont formulées pour aider l'équipe à s'approprier le problème. Il y a certains problèmes qui semblent échapper au contrôle de l'équipe (centre de données perdant de l'énergie, etc.). Mais même dans de tels événements, l’équipe peut encore améliorer sa réaction face au désastre.
Étape 3 : Détecter – Comment détecter ce problème ou un problème similaire plus tôt ?
Supposez que ce problème ou un problème très similaire se reproduira. Comment l'équipe de service d’assistance peut-elle détecter ce problème plus rapidement et le trouver avant qu'un client ne le fasse ?
Étape 4 : Réagir – Comment pouvons-nous améliorer notre réponse à ce type de problème ?
Supposons que le ticket soit signalé. Quelle a été la rapidité de la réaction ? Des minutes ont-elles été perdues pendant que des personnes envoyaient des e-mails pour essayer d'amener quelqu'un à examiner le problème ?
La prochaine fois que ce ticket se produit, comment l'équipe peut-elle réagir plus rapidement ou de manière plus organisée ?
Étape 5 : Solution rapide – Comment arrêter l'hémorragie plus vite ?
Lorsque cela se produit de nouveau, y a-t-il une solution de contournement prête que nous puissions fournir au client pour réduire l'impact du problème ?
Si cela s'aggrave avec le temps (comme une attaque DDoS), avons-nous un moyen rapide de fermer les vannes pendant que nous identifions la cause principale ?
Étape 6 : Prévenir – Comment prévenir ou réduire l'impact de problèmes similaires à l'avenir ?
C'est souvent la seule question que les équipes posent lors d'un postmortem. C'est une question importante et vous devriez y passer beaucoup de temps. Cependant, si vous vous limitez à demander uniquement comment prévenir un ticket, cela vous permet de ne pas prendre de responsabilité pour les éléments sous votre contrôle (comme la manière dont vous détectez, réagissez ou corrigez rapidement un ticket).
Lorsque vous faites un brainstorming d'idées, ne vous limitez pas à des solutions techniques. Une meilleure surveillance, de meilleurs chemins de communication, de meilleures formations, s'assurer que les personnes du service client connaissent par nom les personnes du support de production, etc.
Étape 7 : Autres zones de risque – Quelles autres zones partagent cette même vulnérabilité ?
Chaque ticket est un indice de la faiblesse de votre système. Il y a de fortes chances que pour chaque ticket que vous trouvez, il y en ait des dizaines cachés dans l'ombre, encore à découvrir.
Un peu comme si vous voyez une souris dans votre cuisine. Vous n’avez pas un problème de « souris », mais un problème de « souris ».
Il est probable que d'autres parties du système partagent les mêmes hypothèses de conception ou, dans certains cas, le même code (bien que personne ne copierait/collerait jamais de code).
Passez quelques minutes à faire un brainstorming sur d'autres endroits qui sont vulnérables de manière similaire.
Lorsque les équipes sont stressées et surchargées de travail, elles passent cette étape. Je trouve qu'il s'agit de la question la plus importante à poser pour amener l'équipe à adopter un état d'esprit proactif et à réduire le nombre de problèmes à l'avenir.
Étape 8 : Prochaines étapes (Actions)
Après avoir identifié toutes les actions possibles pour améliorer la détection, la réaction, la correction rapide et la prévention des tickets, et trouvé les autres zones de votre application nécessitant une attention particulière, passez à la décision des actions à entreprendre.
La manière dont vous hiérarchisez cela dépend de vous. En revanche, j’ai quelques conseils à vous donner.
Obtenez un nom et une date pour chaque élément que vous projetez de traiter avant de quitter la réunion.
Si quelqu'un dans la réunion est passionné par la réalisation d'une des actions, encouragez-le, même si vous pensez que ce n'est peut-être pas la chose la plus importante à résoudre.
Noms et dates
En général, j’ai constaté que les équipes apprécient cet exercice (à condition que vous puissiez créer un environnement sans reproches pour la réunion). Ils aiment disséquer le problème et faire un brainstorming de solutions. Cependant, tout le monde se sent occupé et débordé. À moins que cette réunion ne se termine avec des propriétaires et des dates à côté des choses à faire, il est fort probable qu'aucune des améliorations ne se concrétise.
Ce qui va se passer, c'est que dans 3 semaines, lorsque le même problème se reproduira en production (mais cette fois de manière plus importante), quelqu'un dira : « Ah oui, nous avons parlé de le résoudre. » Pas un endroit idéal où être.
Pour pallier cela, assurez-vous simplement qu'il y a un nom et une date à côté de chaque action que le groupe veut entreprendre.
Basé sur le Blameless Postmortem Canvas de David Frink.
Commencer avec ce modèle maintenant.
Jeu d'itération de puzzle Scrum
Idéal pour:
Agile, Jeux, Icebreaker
Le jeu de l'itération du puzzle Scrum est une activité pratique qui renforce les principes et pratiques Scrum. En simulant des cycles de développement itératifs à travers la résolution d'énigmes, les équipes apprennent l'importance de la collaboration, de l'adaptabilité et de l'amélioration continue. Ce modèle offre une manière amusante et engageante d'internaliser les concepts Scrum et d'améliorer le travail d'équipe, permettant aux praticiens Agile de délivrer de la valeur plus efficacement.
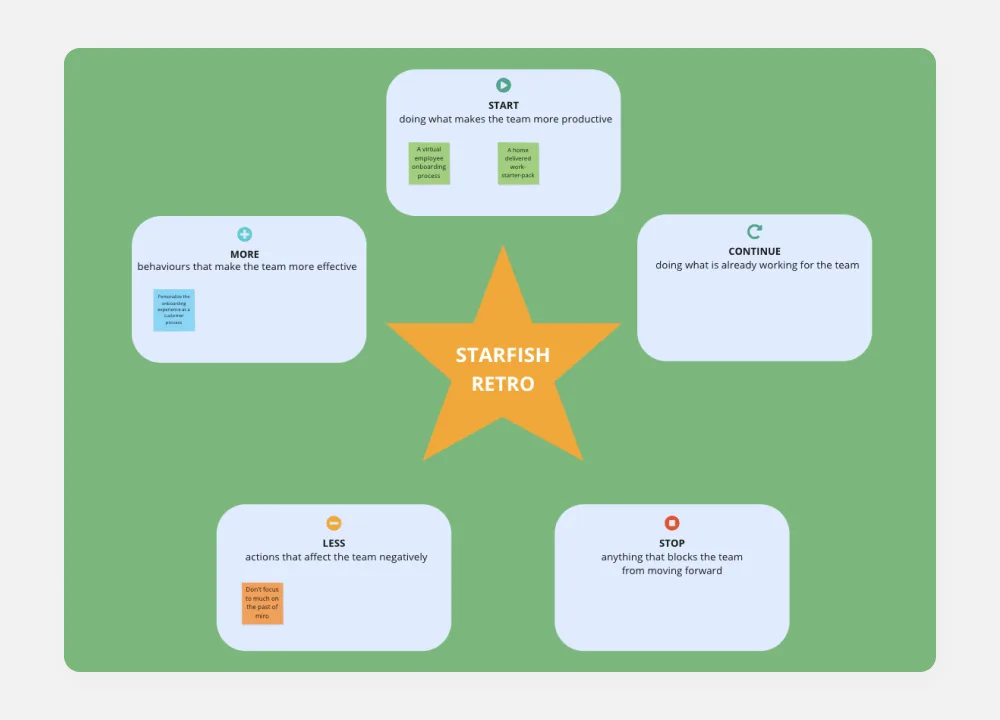
Rétrospective Starfish
Idéal pour:
Rétrospectives, Méthodologie Agile, Réunions
Le modèle de rétrospective Starfish offre une approche structurée pour les rétrospectives en utilisant la métaphore de l'étoile de mer. Il fournit des éléments pour identifier ce qu'il faut commencer, arrêter, continuer, faire plus et faire moins. Ce modèle permet aux équipes de réfléchir sur les itérations passées, d'identifier des insights exploitables et de prioriser les améliorations. En favorisant la clarté et la concentration, la Rétrospective Étoile de Mer permet aux équipes d'initier des changements significatifs et d'amorcer une amélioration continue de manière efficace.
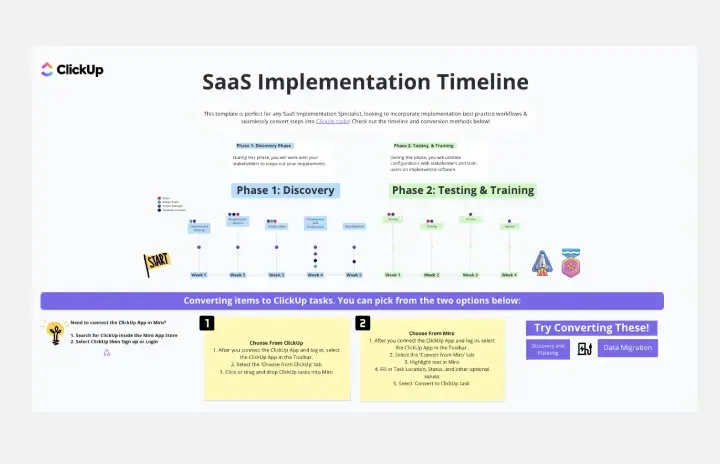
Planning d'implémentation SaaS
Idéal pour:
Agile
Le modèle de planning pour la mise en œuvre de SaaS offre une feuille de route visuelle pour planifier et suivre la mise en œuvre de solutions de Software as a Service (SaaS). Il fournit un cadre structuré pour définir les jalons, allouer les ressources et suivre les progrès. Ce modèle permet aux organisations de gérer les déploiements SaaS efficacement, garantissant une adoption réussie et la réalisation de la valeur commerciale. En favorisant la transparence et la responsabilité, le Planning de mise en œuvre du SaaS permet aux équipes de livrer les projets dans les délais et le budget prévus, renforçant ainsi l'agilité et la compétitivité organisationnelle.

Roadmap produit Agile
Idéal pour:
Roadmap, Planification, cartographie
Le modèle de Roadmap produit Agile permet aux équipes de visualiser et de communiquer la direction stratégique de leur développement produit dans un environnement Agile. Il permet la flexibilité et l'adaptation aux exigences changeantes tout en offrant une vue d'ensemble claire des priorités et du planning. En incorporant des boucles de rétroaction et une planification itérative, les équipes peuvent s'assurer de l'alignement avec les attentes des parties prenantes et livrer de la valeur de manière incrémentale.
Modèle de rétrospective : boucle d’apprentissage
Idéal pour:
Rétrospectives, Agile
Le modèle de rétrospective en boucle d'apprentissage est un outil puissant conçu pour aider les équipes à réfléchir sur leurs projets en reconnaissant les réussites et en identifiant les domaines d'amélioration. Ce modèle fait partie des modèles intelligents de Miro, qui rationalisent les workflows et maintiennent l'engagement des équipes en intégrant l’IA, des outils interactifs et des intégrations fluides. L'un des principaux avantages du modèle de rétrospective en boucle d'apprentissage est sa capacité à favoriser l'amélioration continue. En réfléchissant régulièrement à leur travail et en identifiant les domaines d'amélioration, les équipes peuvent constamment améliorer leurs performances et obtenir de meilleurs résultats.

Puzzle Scrum
Idéal pour:
Agile
Le Puzzle Scrum est une activité collaborative qui renforce les rôles, les artefacts et les cérémonies Scrum. En assemblant un puzzle représentant le cadre Scrum, les équipes acquièrent une compréhension plus approfondie de ses composantes et de leurs interrelations. Ce modèle offre un moyen amusant et interactif de renforcer les connaissances Scrum et de promouvoir l'alignement de l'équipe, en permettant aux praticiens d'appliquer les principes Scrum efficacement et de délivrer de la valeur avec agilité.