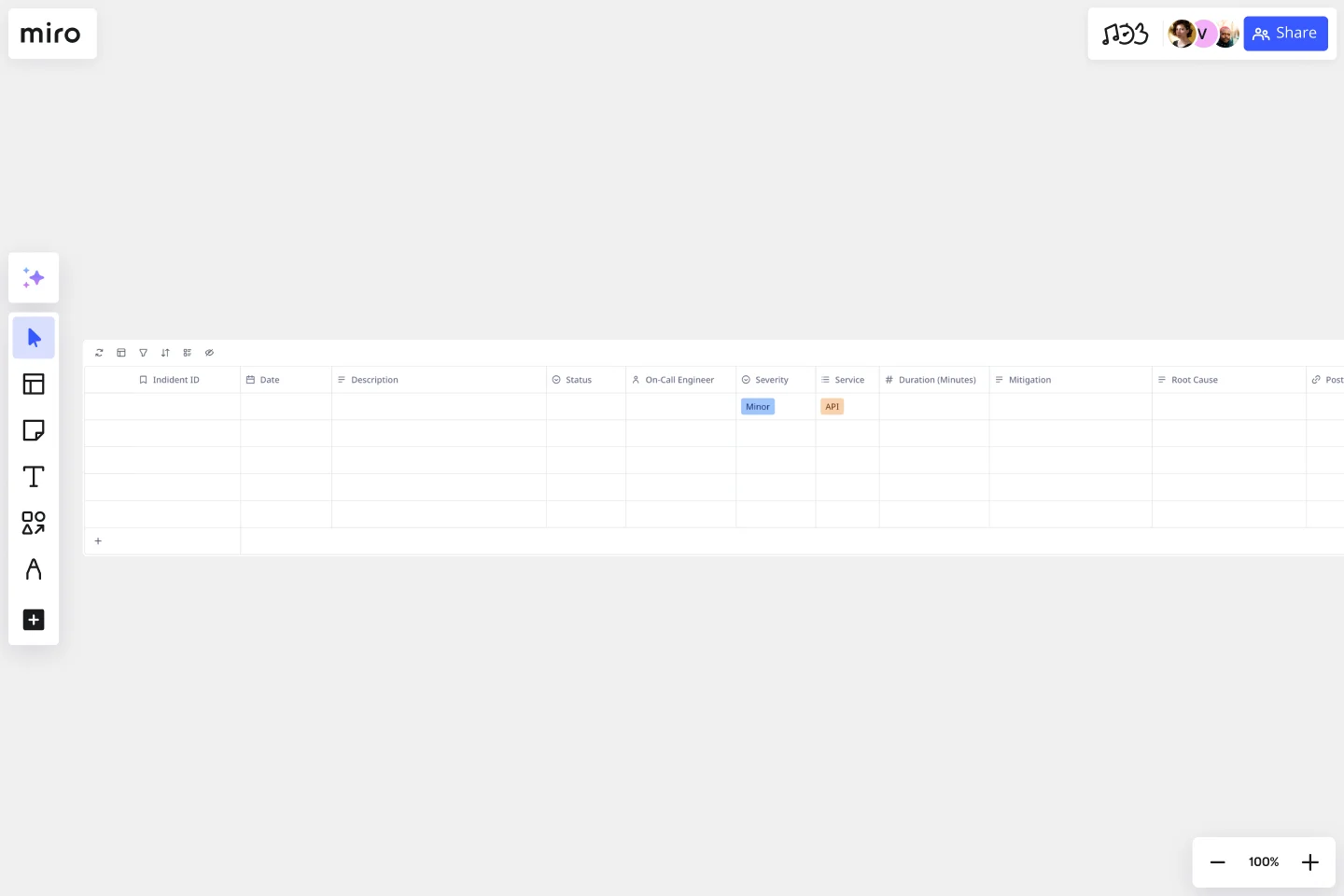
Bereitschaftsdienst-Vorfallsprotokoll-Vorlage
Erfasse die Grundursachen und erkenne schnell wiederkehrende Probleme.
Über die Bereitschaftsdienst-Vorfallsprotokoll-Vorlage
Eine Bereitschaftsdienst-Vorfallsprotokoll-Vorlage revolutioniert die Art und Weise, wie Engineering-Teams Systemvorfälle von der ersten Warnung bis zur endgültigen Lösung erfassen, verfolgen und analysieren. Mit der leistungsstarken Tabellen-Funktion von Miro erstellt diese Vorlage ein strukturiertes Hub, in dem alle Vorfalldetails an einem zugänglichen Ort gespeichert sind – von Schweregraden und Reaktionszeiten bis hin zur Ursachenanalyse und Folgemaßnahmen.
Stellen Sie sich das als Ihr Vorfall-Kommandozentrum vor, das nicht verschwindet, wenn die Krise endet. Anstatt wertvolle Erkenntnisse in der Eile zur Wiederherstellung des Dienstes zu verlieren, bauen Sie eine umfassende Datenbank auf, die Muster aufdeckt, die Teamleistung verfolgt und Ihre Zuverlässigkeitsverbesserungen leitet.
Miro unterstützt sowohl die Echtzeit-Zusammenarbeit während aktiver Vorfälle als auch die asynchrone Post-Mortem-Analyse, sodass eure verteilten Teams effektiv koordinieren können, egal ob sie um 3 Uhr morgens Brände bekämpfen oder in der nächsten Woche gründliche Überprüfungen durchführen.
Wie du die Bereitschaftsdienst-Vorfallsprotokoll-Vorlage von Miro verwendest
Verwandle deinen Vorfallsreaktionsprozess mit diesen sechs Schritten, die reaktive Brandbekämpfung in proaktive Systemverbesserung umwandeln.
1. Richte deine Vorfallsverfolgungsstruktur ein
Beginne damit, die Spalten der Vorlage anzupassen, damit sie dem Workflow deines Teams entsprechen. Konfiguriere Felder für Vorfalls-ID, Zeitstempel, betroffene Dienste, Schweregrade und zugewiesene Ingenieure. Miro-Tabellen sind flexibel – füge benutzerdefinierte Felder für deine spezifische Infrastruktur, Eskalationsverfahren oder Compliance-Anforderungen hinzu.
Deine Vorlage wird zu einem lebendigen Dokument, das mit der Komplexität deines Systems wächst, anstatt ein starres Framework zu sein, das dich in fremde Prozesse zwingt.
2. Echtzeit-Erfassung von Vorfällen einrichten
Wenn Warnmeldungen ausgelöst werden, kann dein Bereitschaftsingenieur den Vorfall sofort direkt in Miro protokollieren. Erfasse die anfänglichen Symptome, die betroffenen Nutzer und die vorläufige Auswirkungenbewertung, solange die Details noch frisch sind. Die Echtzeit-Zusammenarbeit von Miro bedeutet, dass dein gesamtes Reaktionsteam sofortige Updates sieht, egal ob sie über ihren Laptop oder ihr mobiles Gerät beitreten.
Verwende Miro AI, um Vorfallsbeschreibungen zu strukturieren und relevante Tags basierend auf vorherigen ähnlichen Vorfällen vorzuschlagen. Dies beschleunigt den Protokollierungsprozess, wenn jede Minute zählt.
3. Koordination der Reaktionen visuell verfolgen
Neben dem bloßen Protokollieren von Daten, erstelle visuelle Zeitachsen und Abhängigkeitskarten direkt neben deinen Vorfallsaufzeichnungen. Wenn mehrere Dienste betroffen sind, nutze das visuelle Canvas von Miro, um die Kaskade von Ausfällen zu kartieren und parallele Wiederherstellungsbemühungen zu koordinieren.
Dein Vorfallsprotokoll wird mehr als nur eine Tabelle – es wird zu einem Kommandozentrum, in dem technische Details auf visuelle Klarheit treffen.
4. Kollaborative Ursachenanalyse ermöglichen
Nachdem die akute Krise vorüber ist, unterstützt deine Vorlage umfassende Nach-Untersuchungen. Verwende übergeordnete-untergeordnete Beziehungen in Tabellen, um Vorfälle mit ihren zugrunde liegenden Ursachen zu verknüpfen, und erstelle visuelle Diagramme, die die Fehlerkette vom Auslöser bis zur Lösung nachzeichnen.
Teams können asynchron an der Rekonstruktion der Zeitachse zusammenarbeiten und dabei ihre Perspektiven und Erkenntnisse einbringen, ohne endlose Meetingschleifen.
5. Muster mit erweiterten Filtern analysieren
Miros Filter- und Sortierfunktionen verwandeln deine Vorfallsammlung in umsetzbare Erkenntnisse. Erkenne schnell deine häufigsten Fehlerursachen, verfolge Trends bei der durchschnittlichen Lösungszeit und entdecke bedenkliche Muster in verschiedenen Diensten oder Zeiträumen.
Formelfelder berechnen automatisch wichtige Kennzahlen wie Verfügbarkeitsprozentsätze und Eskalationsraten, sodass du die Daten für Kapazitätsplanung und Zuverlässigkeitsgespräche erhältst.
6. Kontinuierliche Verbesserung vorantreiben
Verbinde deine Vorfalls-Erkenntnisse mit Maßnahmen, indem du Kanban-Ansichten innerhalb desselben Arbeitsbereichs nutzt. Wandele die Ergebnisse der Ursachenanalyse in priorisierte Engineering-Aufgaben um und verfolge den Fortgang der Abhilfemaßnahmen parallel zu deinem Vorfallsverlauf.
Dein Vorfallsprotokoll wird zur Grundlage für Zuverlässigkeits-Roadmaps und nicht nur zu einem Eintrag vergangener Probleme.
Was sollte in einer Vorlage für ein Bereitschaftsdienst-Vorfallsprotokoll enthalten sein?
Jedes Engineering-Team hat einzigartige Anforderungen an die Vorfallreaktion, aber diese Kernelemente schaffen eine umfassende Grundlage für Lernen und Verbesserungen.
Vorfallidentifikation und Zeitachse
Erfasse die wesentlichen wer, was, wann Details, die den Rahmen jedes Vorfalls bilden. Schließe eindeutige Kennungen, Discovery-Zeitstempel, Lösungszeiten und die vollständige Chronologie der Reaktionsmaßnahmen ein. Diese Zeitachse wird entscheidend für die Nachanalyse von Vorfällen und die Identifizierung von Engpässen in deinem Reaktionsprozess.
Auswirkungs- und Schweregradbewertung
Dokumentiere den Ausbreitungsradius jedes Vorfalls – betroffene Dienste, Nutzerbeeinträchtigungen, Umsatzfolgen und externe Abhängigkeiten. Klare Schweregradklassifizierungen helfen bei Eskalationsentscheidungen und der Ressourcenzuteilung während aktiver Vorfälle.
Koordination des Reaktionsteams
Verfolge, wer geantwortet hat, wann sie sich angeschlossen haben und welche Maßnahmen sie ergriffen haben. Diese Informationen helfen bei der Planung des Bereitschaftsdienstes, identifizieren Wissenslücken und stellen sicher, dass die Ingenieure, die deine Systeme am Laufen gehalten haben, die Anerkennung erhalten.
Ursachen- und Lösungsdetails
Der wertvollste Teil eines jeden Vorfallsprotokolls ist das Lernen. Erfasse nicht nur, was kaputtgegangen ist, sondern auch, warum es kaputtging, was es behoben hat und was ähnliche Fehler verhindern könnte. Diese Erkenntnisse lenken deine Investitionen in Zuverlässigkeit und architektonische Entscheidungen.
Nachverfolgungsmaßnahmen und Verbesserungen
Wandle Erkenntnisse nach einem Vorfall in nachvollziehbare Handlungspunkte um. Verknüpfe Behebungsaufgaben mit den ursprünglichen Vorfällen, damit du die Effektivität deiner Zuverlässigkeitsverbesserungen im Laufe der Zeit messen kannst.
How does this template integrate with existing incident management tools?
Miro's incident log template complements your existing alerting and ticketing systems rather than replacing them. Use it as your central coordination hub where scattered information from PagerDuty, monitoring dashboards, and communication channels comes together in a visual format. The template captures the human context and collaborative analysis that traditional tools often miss.
Can remote teams effectively use this during critical incidents?
Absolutely. Miro's real-time collaboration features are built for distributed teams working under pressure. Multiple engineers can update the incident log simultaneously, add visual context with diagrams, and maintain shared situational awareness even when spread across time zones. The mobile-friendly interface ensures your on-call engineers can log details from anywhere.
How does this help with compliance and incident reporting?
The structured format and comprehensive audit trail make compliance reporting much simpler. Export incident data for regulatory requirements, generate executive summaries with visual timelines, and maintain the detailed documentation needed for post-incident reviews. Formula fields can automatically calculate SLA metrics and availability statistics.
What makes this better than spreadsheet-based incident logs?
While spreadsheets capture data, they don't support the visual collaboration that complex incident response requires. Miro combines structured data management with visual thinking – you can create system diagrams, timeline visualizations, and collaborative analysis directly alongside your incident records. Plus, real-time collaboration means no more version control nightmares during critical outages.
Wie oft sollten Teams ihre Vorfallsprotokolldaten überprüfen?
Dein Vorfallsprotokoll sollte eine lebendige Ressource sein und nicht nur ein Archiv. Überprüfe wöchentlich bei Team-Synchronisationsmeetings die aktuellen Vorfälle, führe monatlich eine Musteranalyse durch, um Trends zu identifizieren, und nutze vierteljährliche Überprüfungen, um die Wirksamkeit vorheriger Abhilfemaßnahmen zu bewerten. Die visuelle Natur von Miro macht diese Überprüfungen ansprechender und handlungsorientierter als die herkömmliche Excel-Analyse. Letztes Update: 7. August 2025
Beginne jetzt mit diesem Template
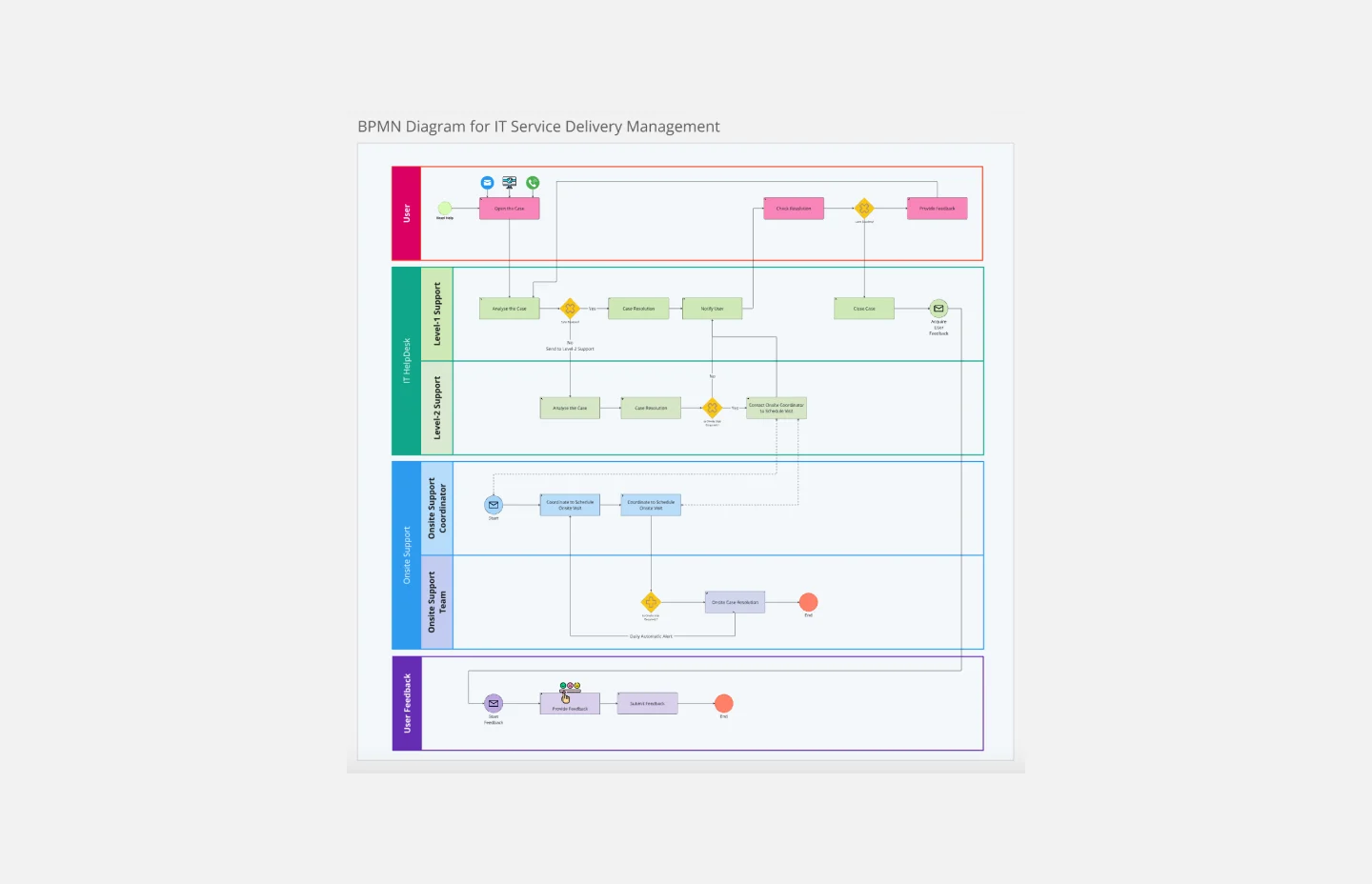
BPMN für IT-Service-Delivery-Management
Ideal für:
BPMN
Die BPMN-Diagrammvorlage für IT-Prozesse bildet IT-Workflows ab und optimiert sie, von der Fehlerverwaltung bis zur Servicebereitstellung. Ideal für IT-Teams, die das Servicemanagement verbessern, Abläufe optimieren und die Servicequalität steigern möchten, bietet diese Vorlage einen visuellen Rahmen zur Identifizierung von Engpässen, Verbesserung der Kommunikation und effizienten Verwaltung von IT-Prozessen.
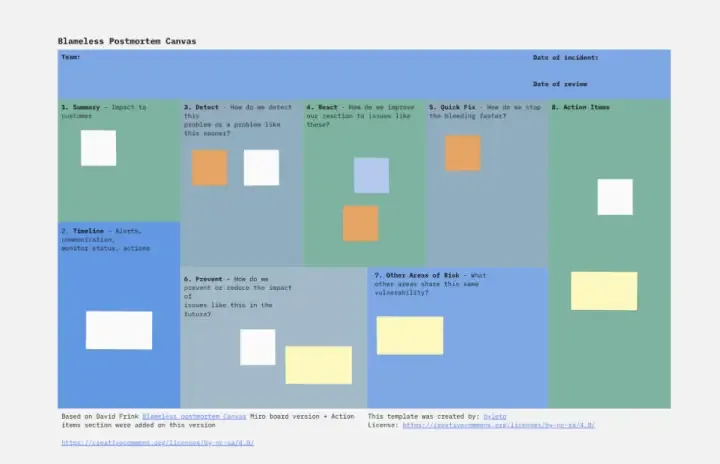
Blameless Canvas für Nachbearbeitungen
Ideal für:
Agile
Das Blameless Postmortem Canvas ist ein strukturierter Rahmen für die Durchführung von blameless Postmortems nach Vorfällen oder Fehlern. Es bietet Abschnitte zum Dokumentieren der Zeitachse, Auswirkungen, Grundursachen und umsetzbaren Erkenntnisse. Diese Vorlage fördert eine schuldfreie Lern- und Verbesserungskultur, die es Teams ermöglicht, Vorfälle objektiv zu analysieren, systemische Probleme zu identifizieren und vorbeugende Maßnahmen zu implementieren. Die Blameless Postmortem Canvas stärkt durch Förderung von Transparenz und Verantwortung die Fähigkeit von Organisationen, aus Fehlern zu lernen und ihre Resilienz zu erhöhen, was kontinuierliche Verbesserung und Zuverlässigkeit vorantreibt.

Vorlage zur Ursachenanalyse (RCA)
Ideal für:
Strategie, Planung
Die Root-Cause-Analysis (RCA)-Vorlage ist ein strukturiertes Tool, das Teams dabei hilft, die zugrunde liegenden Ursachen spezifischer Probleme oder Ereignisse aufzudecken. Durch das Ermitteln und Angehen dieser Grundursachen, anstatt nur die Symptome zu behandeln, können Organisationen langfristige Lösungen fördern und wiederkehrende Herausforderungen verhindern, was zu effizienteren und nachhaltigeren Abläufen führt.
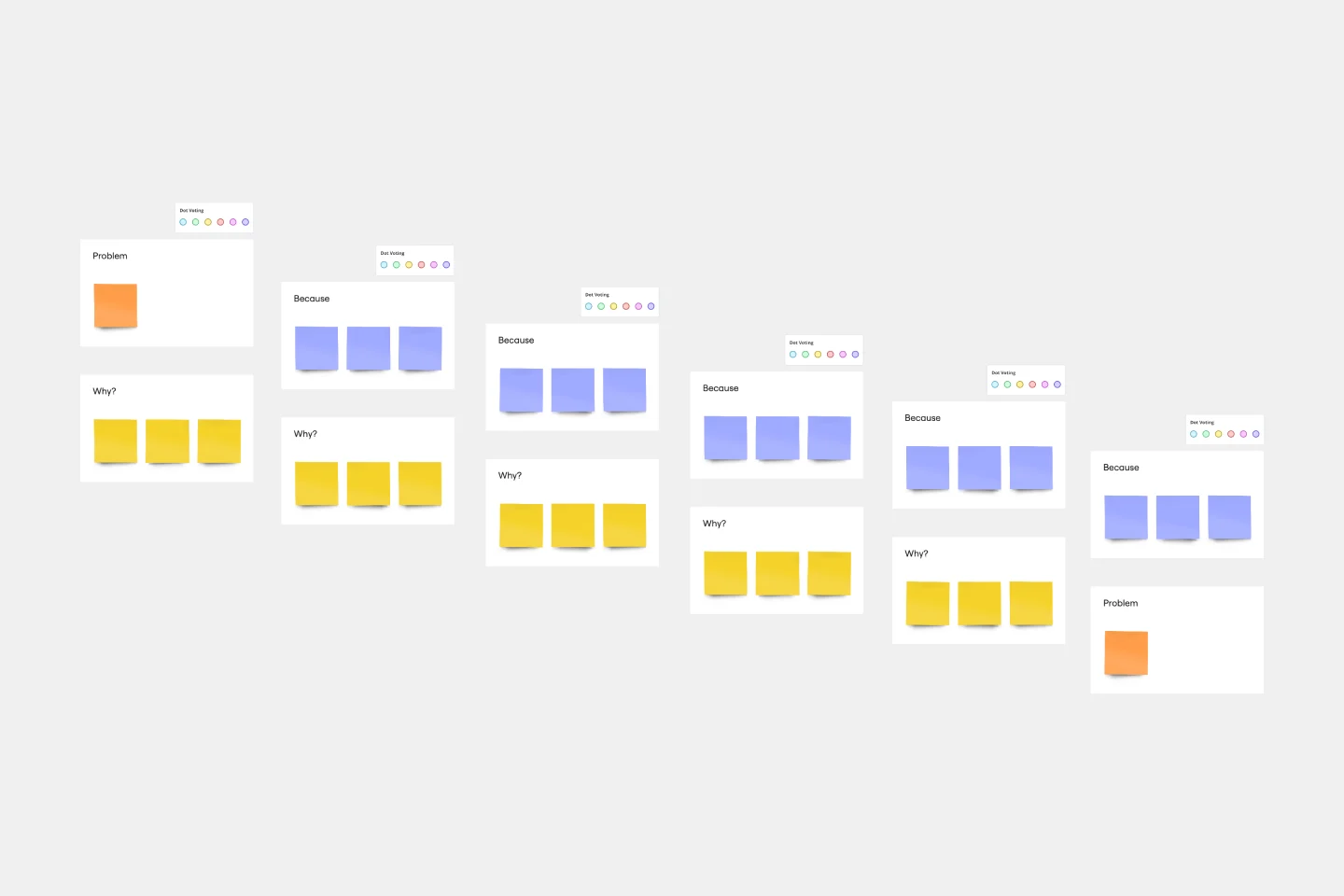
5-Whys-Vorlage
Ideal für:
Design Thinking, Betrieb, Mapping
Bist du bereit, dem Problem auf den Grund zu gehen? Es gibt keinen einfacheren Weg, dies zu tun, als die 5-Whys-Technik. Du beginnst mit einer einfachen Frage: Warum ist das Problem aufgetreten? Dann wirst du bis zu viermal weiterfragen, bis die Antwort klar wird und du auf eine Lösung hinarbeiten kannst. Und Miro's Funktionen verbessern diesen Ansatz: Du kannst Teammitglieder im Chat mit Fragen ansprechen oder sie mit @Erwähnungen in Kommentaren markieren und farbkodierte Notizen verwenden, um auf zentrale Vorgänge des aktuellen Problems hinzuweisen.
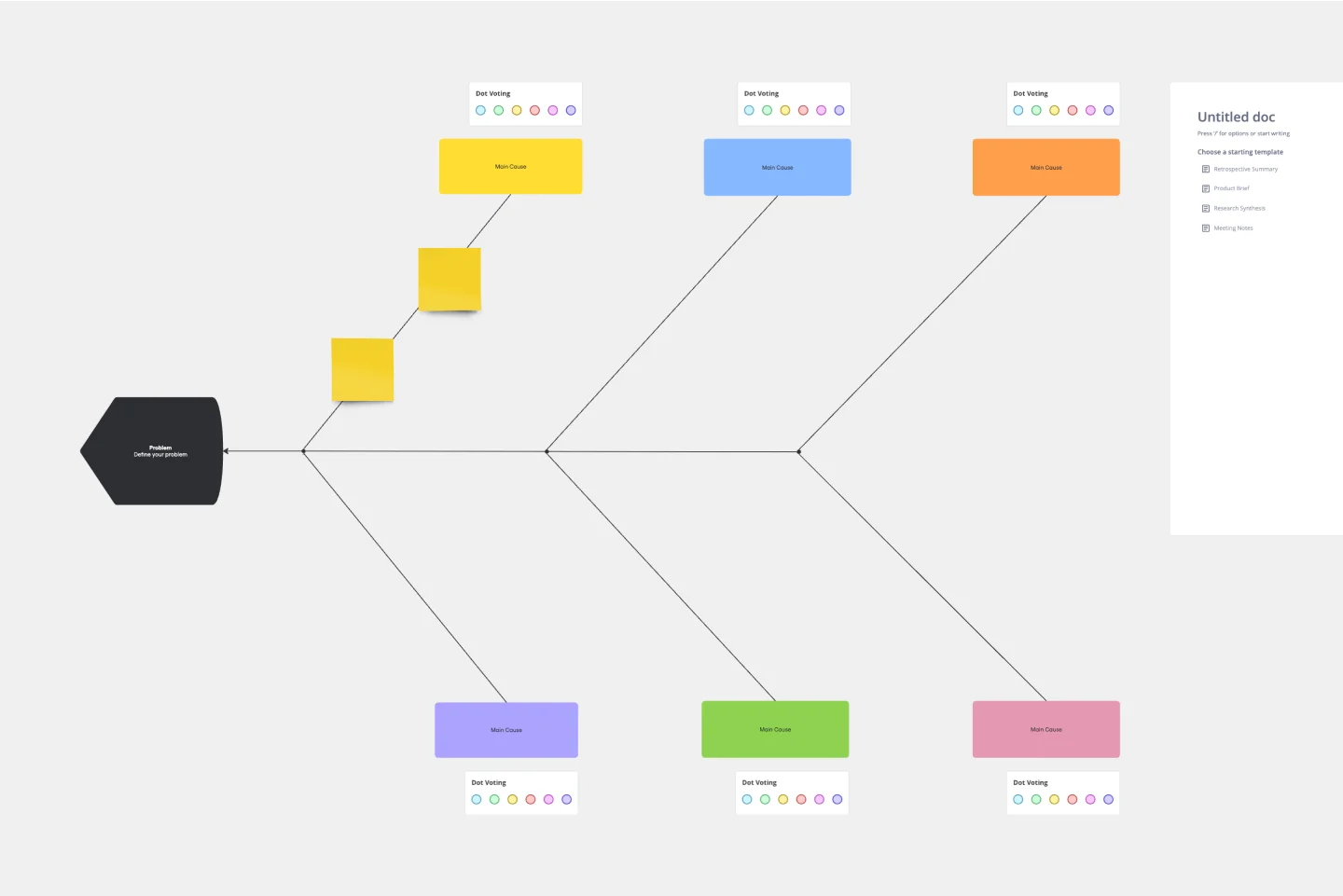
Vorlage für Ishikawa-Diagramm (Ursache-Wirkungs-Diagramm)
Ideal für:
Betrieb, Diagramme, Workflows
Was ist der beste Weg, um jedes Problem zu lösen, dem dein Team gegenübersteht? Geh direkt zur Ursache. Das bedeutet, die Grundursachen des Problems zu identifizieren, und Ursachen-Wirkungs-Diagramme sind so konzipiert, dass sie dir dabei am besten helfen. Auch bekannt als Ishikawa-Diagramm (benannt nach dem japanischen Qualitätskontrollexperten Kaoru Ishikawa), ermöglichen Ursachen-Wirkungs-Diagramme Teams, alle möglichen Ursachen eines Problems zu visualisieren, um zu erforschen und zu verstehen, wie sie sich ganzheitlich zusammenfügen. Teams können Ursachen-Wirkungs-Diagramme auch als Ausgangspunkt nutzen, um darüber nachzudenken, was die Grundursache eines zukünftigen Problems sein könnte.